
画像生成AIの話なのだ
突然ですが
以下の画像の主役は誰だかわかりますか?
天岩戸神話の天照大御神(春斎年昌画、明治22年(1889年))
はい天照大御神ですね。奥の岩影から見える女性ですね。
ChatGPTは優秀 ※参考
はじめに、これは対話を通して文脈を理解できるChatGPTの方が認識させるのは簡単です。
ChatGPTに認識させて描き替えてもらった画像がこちら

奥の人物が主役で女性である事を伝えた↓

ChatGPT
素晴らしい認識能力と文脈理解力です。色々説明すればもっと、元絵の文脈に近づける事が可能でしょう。
ですが、僕のテーマは画像生成AIに認識させやすい絵についての実験なので、これは参考です。
Stable Diffusionに主役を認識させるのが難しい絵がある
Stable Diffusion (2024)で生成した画像がこちら ※i2i




Stable Diffusionは完全に主役を間違えて認識してますね。
この絵を認識させるためにはプロンプトは結構ゴリゴリに入れています。ですが認識させるのは難しかったです。
後光が何処から出ているかとかの画像の文脈がわかれば、後ろの人物が主役だとわかるのですが、画像生成しかできないAIは文脈理解力が弱いので、主役が誰なのかについて、複雑な絵だとうまく伝えるのは難しいです。
加工をすれば主役を認識させやすくなるのですが、この絵に関しては僕は色々加工をしても後ろの人物を主役だと認識させる事はできませんでした。(真ん中の人物が目立ちすぎで、この人物の存在感を薄くすると全く違う絵になる。)
Stable Diffusionに主役を認識させるのに効果的な要素
Stable Diffusionは複雑な文脈的説明よりも、以下の方が主役を認識させるのに効果的です。
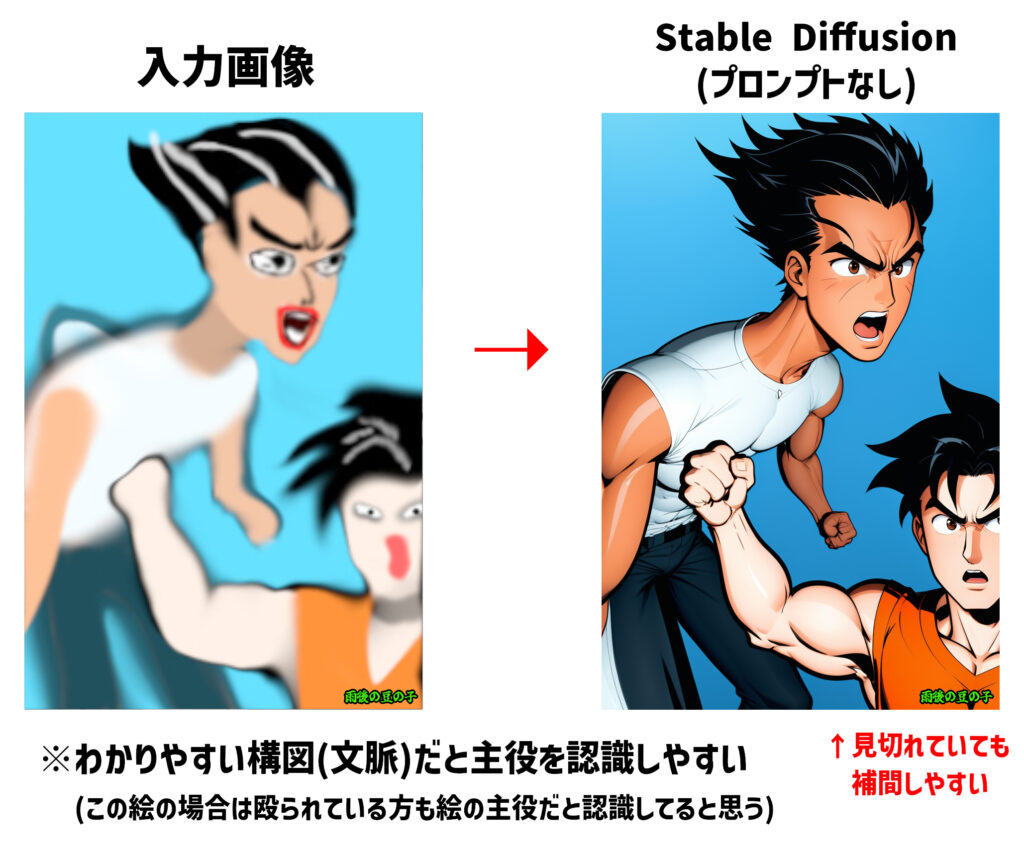
①色や線、形状で。他とは明確に違いがわかるようにする
・大きさや位置は脇でもハッキリ描けば主役として認識する。
②描かれている大きさや位置
・ハッキリしていなくても大きく真ん中の物を主役と認識しやすい。
③わかりやすい状況。簡単に文脈がわかる構図
・簡単なシチュエーションだと主役を認識させやすい。
ぶっ飛ばされているキャラクターの前に殴りかかっているキャラクターを描く等。
例
①色や線、形状で。他とは明確に違いがわかるようにする
・大きさや位置は脇でもハッキリ描けば主役として認識する。
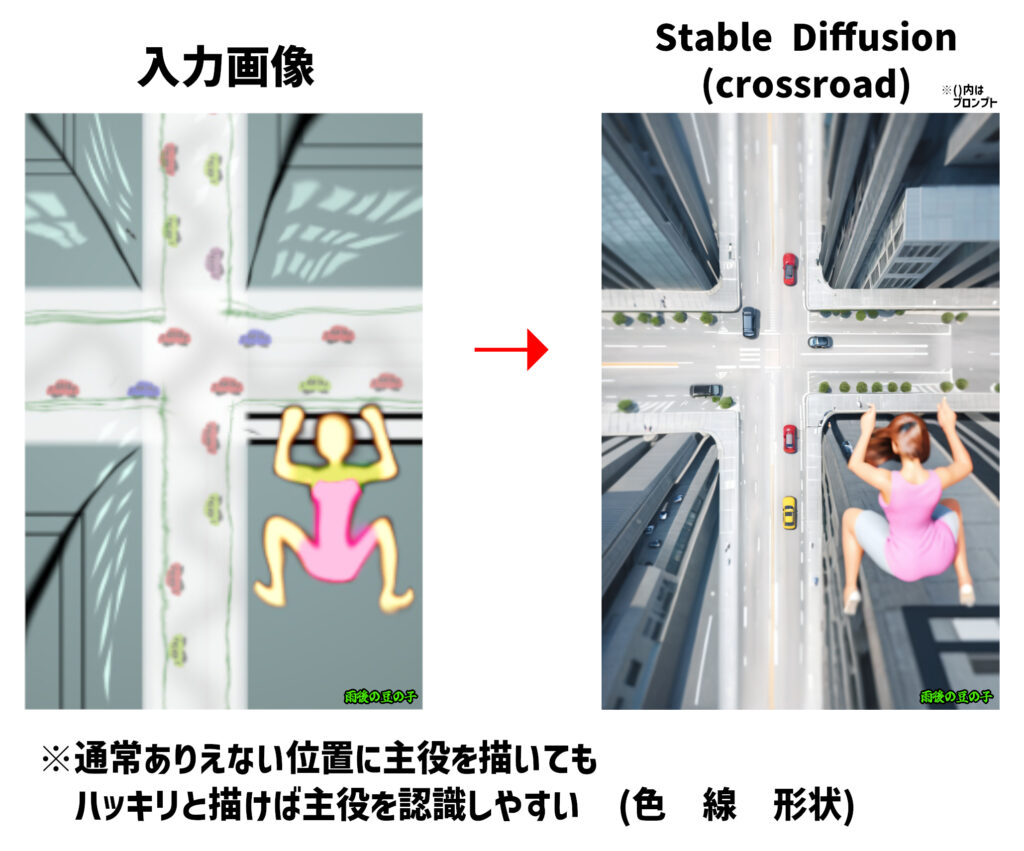
②描かれている大きさや位置
・ハッキリしていなくても大きく真ん中の物を主役と認識しやすい。
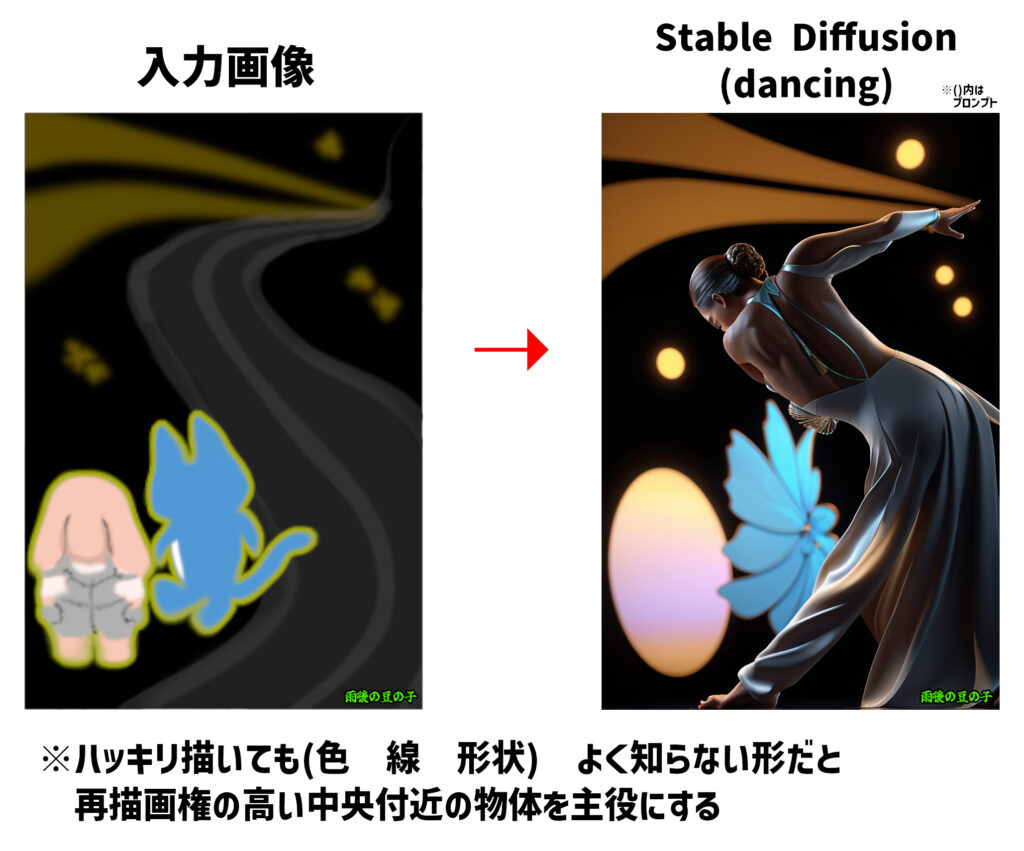
③わかりやすい状況。簡単に文脈がわかる構図
・簡単なシチュエーションだと主役を認識させやすい。
ぶっ飛ばされているキャラクターの前に殴りかかっているキャラクターを描く等。
マルチモーダル方向のAIではあまり有用でないテクニック
マルチモーダルの方向性のAI(ChatGPTやGrok)は文脈を理解する精度が上がっていき、このような技術を使わなくても良くなっていくと予想されます。
※マルチモーダルの方向性のAIとは、色んなAIを統合していく方向で開発が進められているAI。この方向性のAIは文脈理解力が向上していく事が予想されます。現にChatGPTの文脈理解力は凄い所まで来ています。
AI進化の5段階 について 推論力 自律性 創造性(文脈理解)の三つの軸で考える – 私と僕のGPT歴
画像生成AI(特化型)ではまだまだ有用
Stable Diffusionを筆頭にチャットAIとの統合が予定されていない画像生成AIで画像を編集する際には、まだまだ使えるテクニックだと思います。
主役と背景を認識させるテクニックは 既存の画像を認識させる画像加工の際に有用
特に有用な場面は、既存の画像を認識させたい時に画像加工をする場面でしょう。
以下はお見苦しいですが僕が加工した例です。
習うより慣れろという事で
説明は少なめで例は多めです。
例
天使とムハンマド
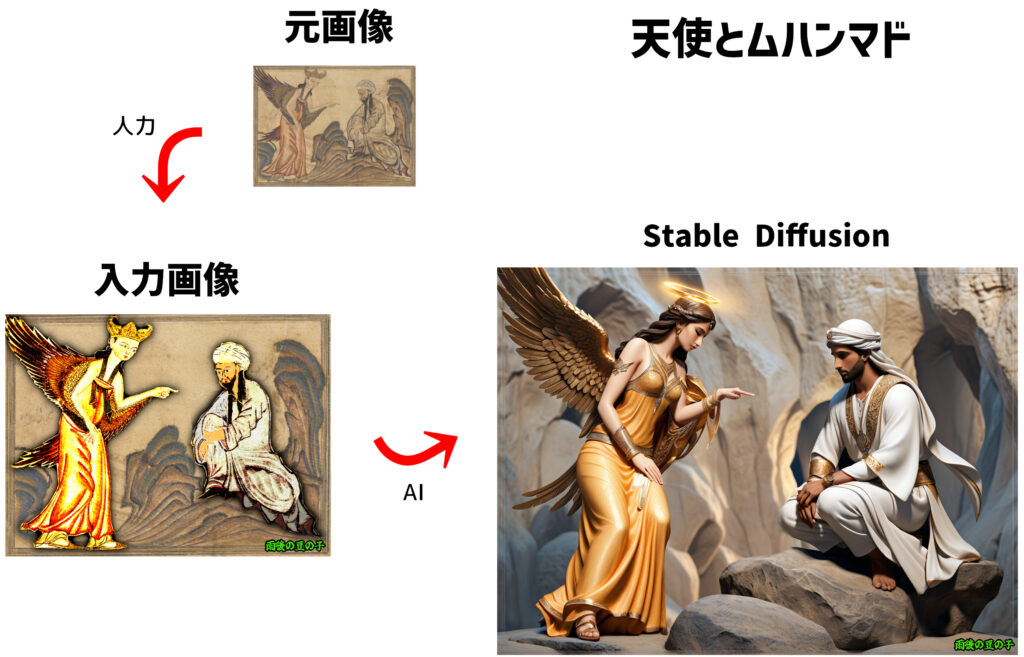
わかりやすく、完成度の高い画像になれば動画生成AIも認識しやすくなる。
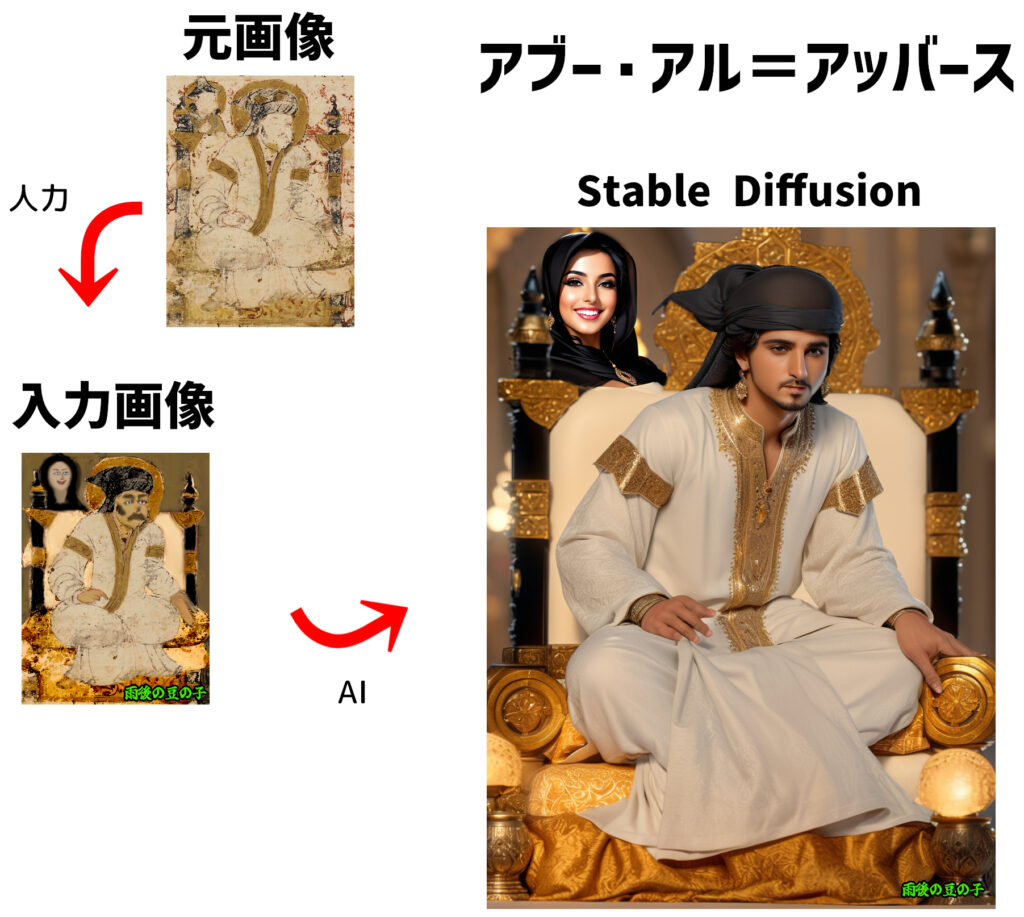
アブー・アル=アッバース
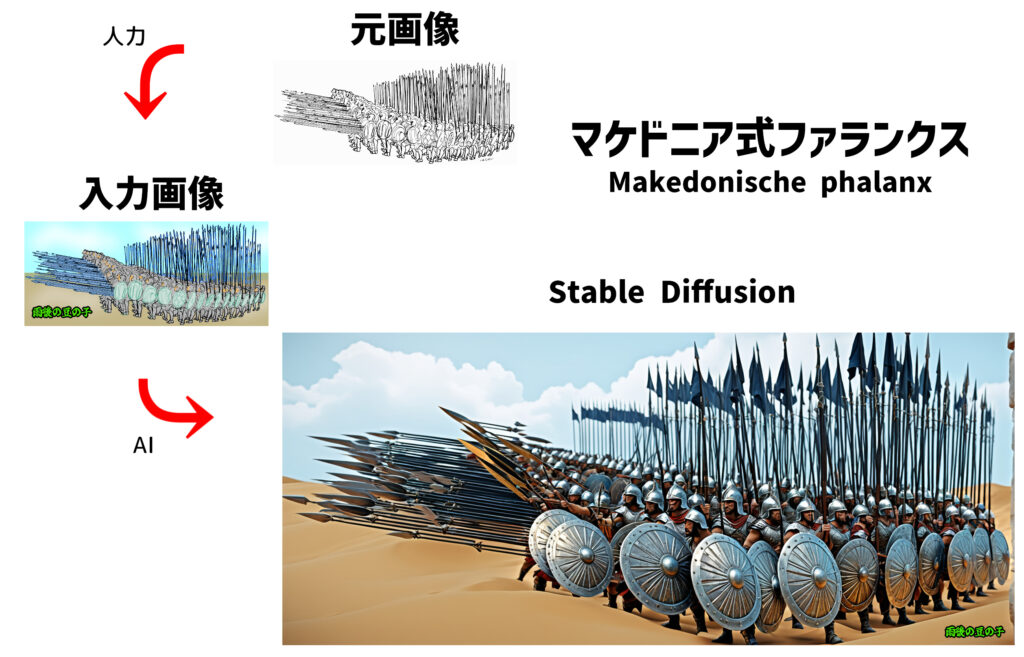
マケドニア式ファランクス
ザマの戦い
(Cornelis Cort,1567)

Hailuoは中国のAIだから途中から建物等が中華風に
結構バグってます。
ザマの戦い
(Henri-Paul Motte, 1890)

微妙な所
象の間に居る馬を認識させる事はできなかった。
象の頭数は減っているし、右端の象は鼻が消えてしまってる。
主役は手前の象と逃げている人と乗ってる人なので、そこをハッキリさせておけば大枠としては文脈的に間違っていない絵をかかせられているので一応満足。
ローマに降伏するマケドニア

あまり元絵と変わらないと思うかもしれないけど、
右端の王様をはっきりさせ、主役の面々と背景の色の差も少し上げている。
また、混同が発生しづらいように、境界に線を描いている。
※正確には王様ではなく執政官。共和制ローマの元首。
ルキウス・アエミリウス・パウルス・マケドニクス – Wikipedia
ローマ vs マケドニア

主役の人物はハッキリ。
主役じゃない人間は背景として、目立たないように。
加工するとAIは認識しやすくなる。
それでも結構バグってますが。
やりすぎはダメ
あまり主役と背景をクッキリさせすぎると、主役はハッキリ認識するけど背景の状況が良くわからなくなってしまうので、これはチェックポイントやAIとどれくらいがちょうどいい塩梅か何回か絵を通して話してみないとわからない。
失敗例

北京占領 (モンゴル帝国)

人数が減っているけど多少はね
バグダッド占領 (モンゴル帝国)
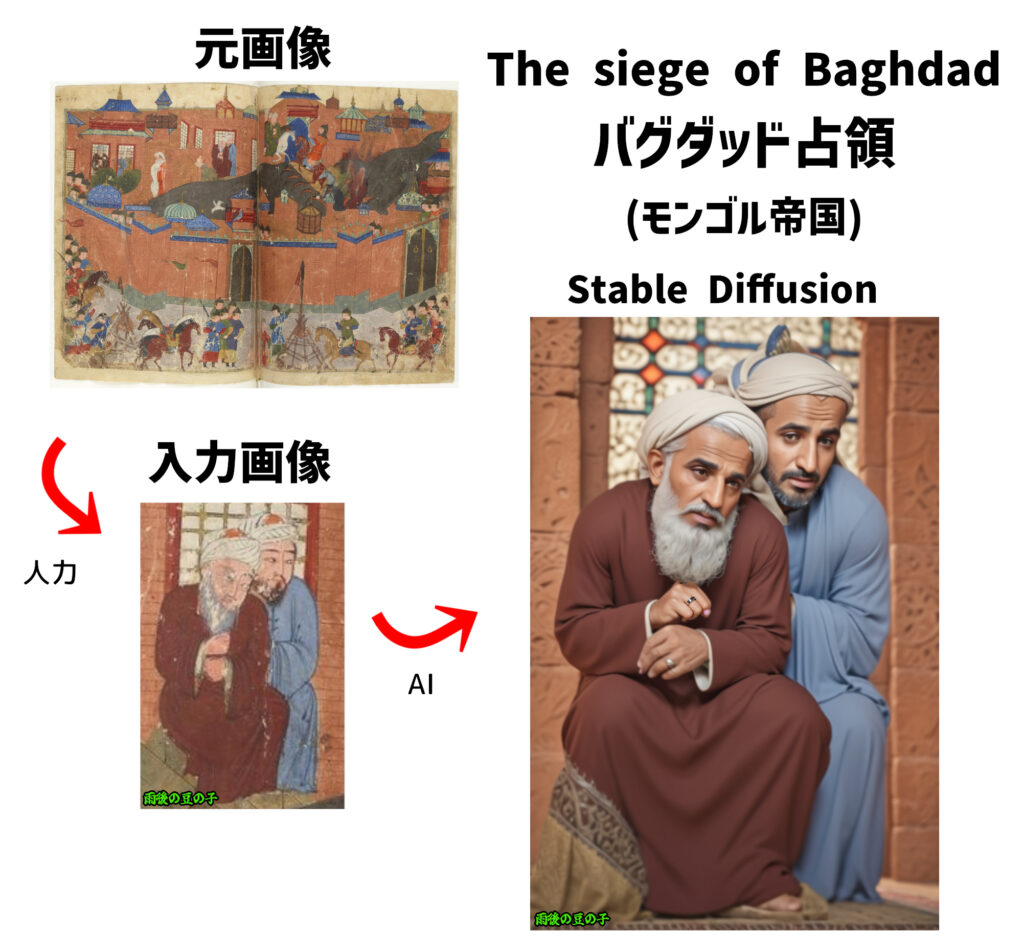
さすがに全体画像を認識させるのは大変だという時は
主役だけ切り抜く
フビライハンの狩

日本占領失敗 (モンゴル帝国)

知らないモノがあるとAIは破綻しやすいので、
鎧等のAIが知らない物は削ってしまう方が構図を認識しやすい。
AIの画像認識は人間で考えると当たり前の事も結構多いのだ。
大事なのは言葉じゃなくて絵を通したAIとの対話なのだ。
コメント