
画像生成AIの話なのだ
時は2023年
画像生成AIを使っていて
僕は思ったのだ。
これプロンプトいらなくね。
以下は僕の実験の一部を動画にしたものだけども、全然視聴者がいなかったので、投稿をやめたのだ。
Stable Diffusionのi2iの動画なのだ。
ChatGPTの画像変更は画像認識の先にあるから、この実験の先にあるモノなのだ。
基本的にプロンプトをいれていないのだ。
NO NEED PROMPT – YouTube
NO NEED PROMPT (@NONEEDPROMPT) / X
僕の仮説 (2023)

現在のAI技術は人間のニューロンとシナプスを模したものであるのだから、
AIがどのように動いているかは、実は詳細にはわからないのだ。
人間と同じように考えると思っていいはずなのだ。
と…すれば、
ある画像パターンをタグ(言葉)と紐づけて、たくさん学習させて覚えさせたとしたら、
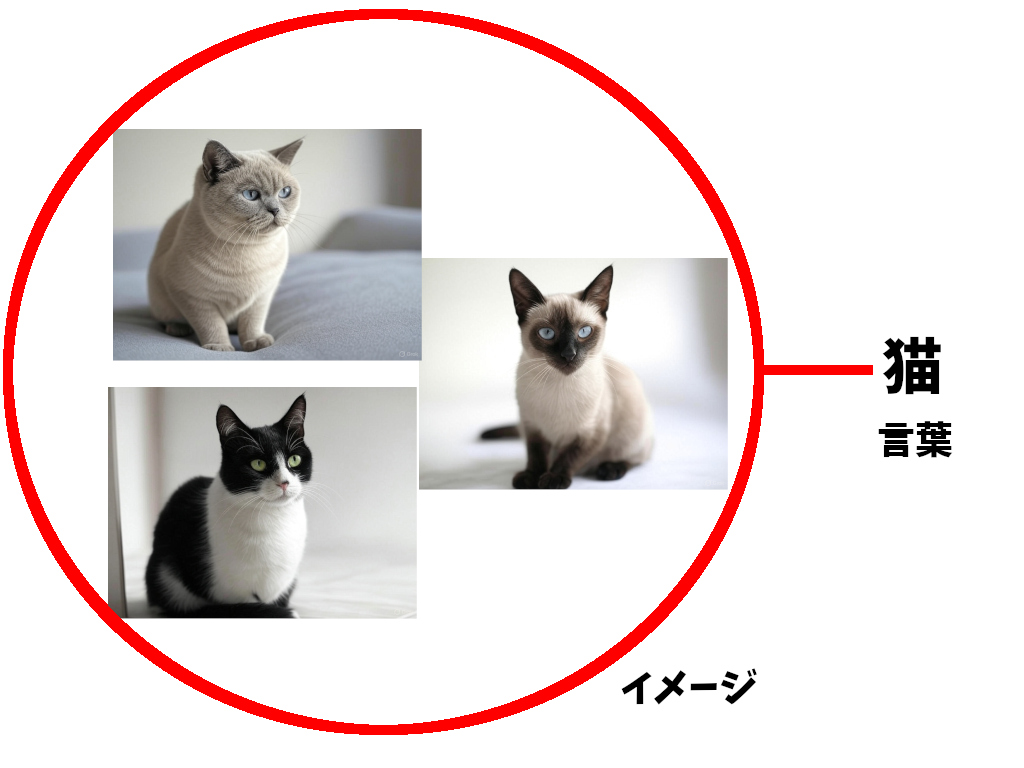
つまり猫の画像を見せて、これは「猫」と言いますよと教え、AIが「猫」を覚えたら、
AIに猫の画像を見せたら、画像認識機能を獲得したチャットAIなら「これは猫です」という。
画像生成AIは文章をアウトプットするようにはできていないから。
言葉では「猫です」とは言ってこない。画像を生成してくる。
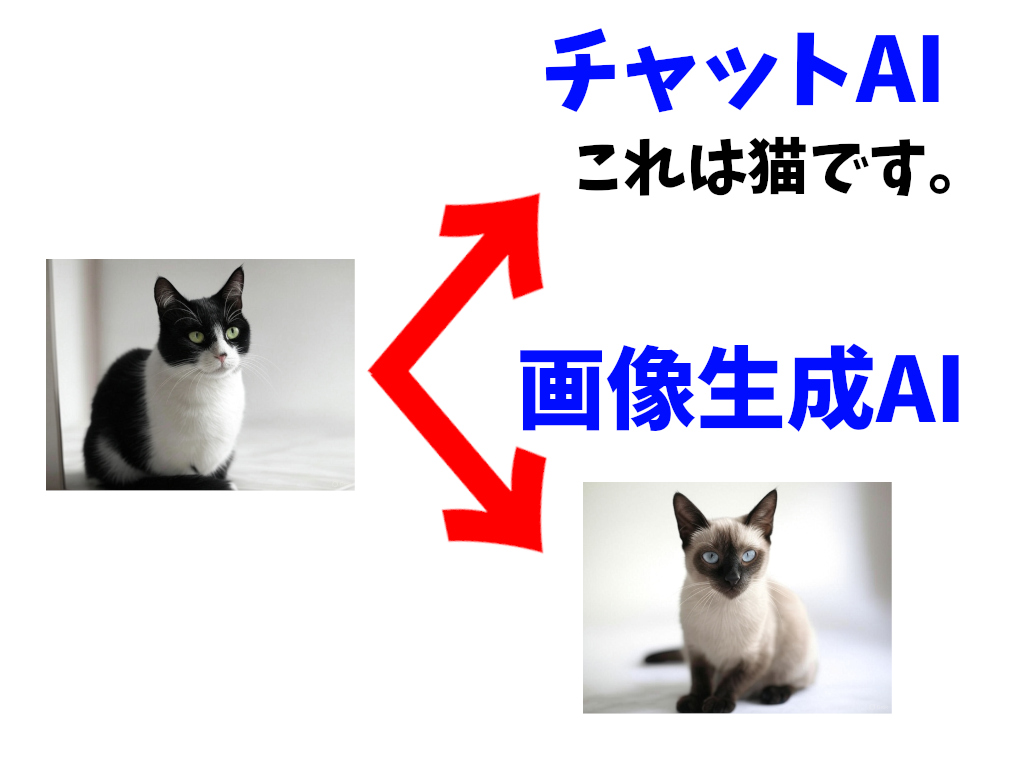
だけど、画像を見たら、僕達人間は、はっきりわかる。
AIはこれを「猫」だと認識したのだと。
AIも人も『猫のイメージ』 と 『猫』 という言葉
これを『別々に覚えて、結び付けている。』
『ある物のイメージ』 と 『自分達の言語では何と言う言葉で表されるか』は頭の中では、
別々に存在し、それが結び付けられている。
写真を見た時に、猫を猫と認識しているけど、
一々全部、これは猫ですとは言わない。
つまり、「猫」というプロンプトを入れずとも、「猫」の画像を見せる事で、
脳は「cat」というプロンプトが入力されたのと同じ状態になる。
それはつまり、AIがどのような形状や色で、
どのように描かれていると該当の物だと認識するかわかっていれば、
プロンプトを入力せずに、自在にAIに絵を描かせる事ができる。
という事でプロンプトをいれないで画像を認識させ、
何に見えるか(何を描くか)、実験を行った。

実験結果の一部は以下の「NO NEED PROMPT」と「雨後の豆の子」のYoutubeかXにアップした動画で確認できるのだ…。
NO NEED PROMPT – YouTube
NO NEED PROMPT (@NONEEDPROMPT) / X
雨後の豆の子 – YouTube
雨後の豆の子 (@UGONOMAMENOKO) / X
これを僕はStable Diffusionのi2iでやった。
どの程度でどのように認識するかは
当たり前だけど、チェックポイントによって差がある。
大枠は同じだけどね。
ChatGPTの画像の解釈能力というのは、
つまる所、僕のこの実験の先にある。
僕の実験の価値は、もしかしたら、人間達はきづかなかったけど、
AIによってピックアップされて、OpenAIには気づかれちゃったかもな…。
最初にやった事 (2023年)
認識の境界を探す
背景 と 主題 をどう分け認識するか (物体の境界)
以下の実験では Phoenix とだけプロンプトをいれている。
参考までにChatGPTにも『この画像を元にフェニックスを描いて』と入力した。
1⃣

『山を描けとは言っていない』のに山を描いて来る
これはプロンプトよりも
元絵が何にに見えるかの方が強く影響を及ぼす場合がある事を示している。
2⃣

3⃣

Stable Diffusionの2⃣と3⃣は設定は同じ = Denoising Strengthは変えていない。
にもかかわらず、元絵を無視するレベルが上がっている。
= 物体と背景の境界の色の差を下げる事でDenoising Strengthを上げたような効果がでている。
AIの認識の境界に影響があるとわかった事
①色の落差
ハッキリした色で境界があると、そこがオブジェクトの境界であると認識しやすい。
②わかりやすい形状
色々やった結果、AIが良く知っている形だと、
その知っているモノだと認識しやすい事がわかった。(バイアス肯定)

③自信のある線
色々やった結果これも影響があるとわかった。
それから他にも以下の様な傾向がある事がわかっている。
アニメ系のチェックポイントは線画で伝えると認識しやすく
リアル系のチェックポイントは陰影で伝えると認識しやすい
境界をわかりにくくするテクニック
オブジェクトの境界をわかりにくくする方法
①色の落差をなくす。
(同じ色で描かれていると同じオブジェクトだと認識しやすい。)

②自信のない線にする。
(ぐにゃぐにゃまげたりして自信のない線にすると オブジェクトの境界がわかりにくくなる。)
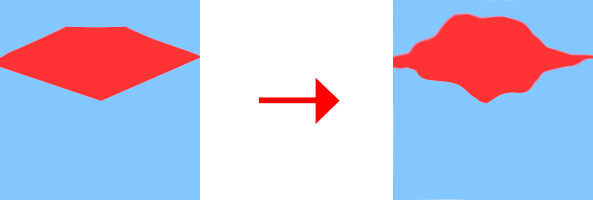
③境界をぼかす。グラデ―ションにする。
(普通にぼかすと境界がわかりにくくなる。)

なんで、境界をわかりにくくするテクニックなんて必要なの?
と思うかもしれないが、これがアルティメットテクニック(究極奥義)なのだ。
はっきりした境界で描かれた完成度の低い絵よりも
何を描いたかはわかるが、境界ははっきりしない絵をAIに渡す事で
AIの再描画権を高く設定した状態でAIに絵を渡す事が可能となり、
最終的な絵の完成度をコントロールする事ができるのだ。
(Denoising Strengthを上げ下げするのと同じような意味合いというか、
Denoising Strengthが同じような事をしている。つまり、
Denoising Strengthを高める=境界をわかりにくくしている
結果 絵の完成度が上がる
Denoising Strengthが低い=元の絵に忠実な絵となる
挙動としては基本的に同じ。)
1. 部分的書き換えをマスク無しで
Denoising Strengthは絵全体に影響してしまうが、
絵によるコントロールは、部分的に影響を与える事ができるのだ。
例えば、
ここは描きかえて欲しいけど、ここは描き変えないで欲しい
と言う部分をマスクなしで指定できるようになる。
例
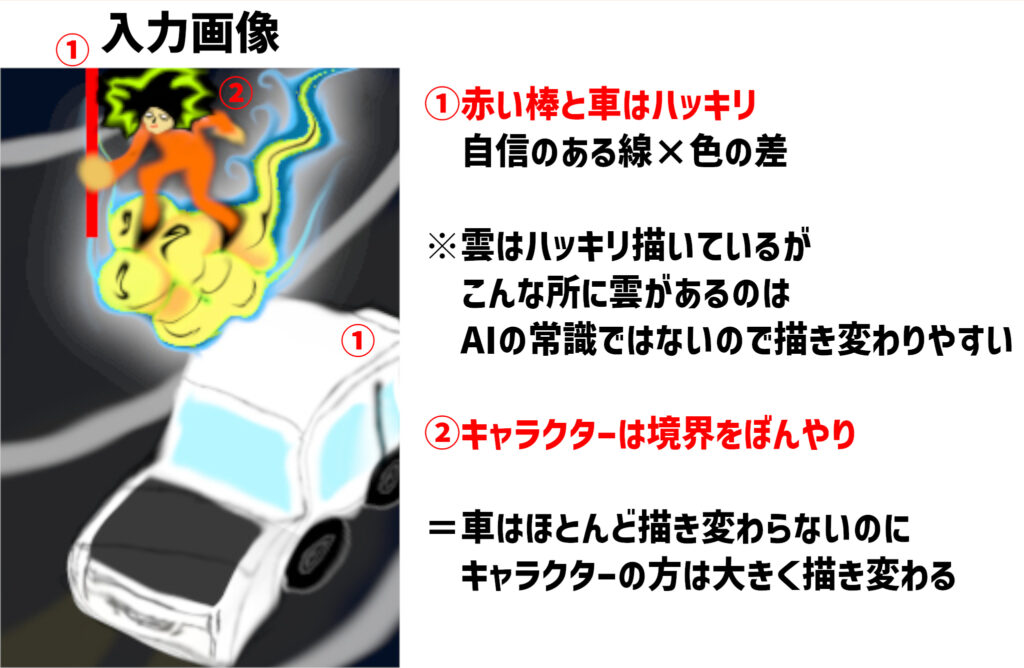

※雲は自分が意図するところではなく、本当はあまり描き変わって欲しくなかったけど、
AIの常識にない絵は相当解釈の余地がない描き方をしないと描き変わりやすい。
2. 何の絵かはわかりやすく、かつ、AIが高い完成度で描きかえてくれる絵。
①色の落差、②自身のない線、③ぼかし、を状況にあわせて使い分ける事で、
表現の幅が広がる。
例えば、
色の落差で同じ物体だとはわかるが、ぼかしや自身のない線によって境界をはっきりさせない事で、AIが何の絵だかは認識しやすいのに、AIが描きかえても良い権利が高い絵をAIに渡す事ができるのだ。

次回は
背景と主役の認識の境目をやるのだ
コメント